
Abstract
Linked data (LD) have the capability to open up and share materials, held in libraries, archives and museums (LAMs), in ways that are restricted by many existing metadata standards. Specifically, LD interlinking can be used to enrich data and to improve data discoverability on the Web through interlinking related resources across datasets and institutions. However, there is currently a notable lack of interlinking across leading LD projects in LAMs, impacting upon the discoverability of their materials. This research describes the Novel Authoritative Interlinking for Semantic Web Cataloguing in Libraries (NAISC-L) interlinking framework. Unlike existing interlinking frameworks, NAISC-L was designed specifically with the requirements of the LAM domain in mind. The framework was evaluated by Information Professionals (IPs), including librarians, archivists and metadata cataloguers, via three user-experiments including a think-aloud test, an online interlink creation test and a field test in a music archive. Across all experiments, participants achieved a high level of interlink accuracy, and usability measures indicated that IPs found NAISC-L to be useful and user-friendly. Overall, NAISC-L was shown to be an effective framework for engaging IPs in the process of LD interlinking, and for facilitating the creation of richer and more authoritative interlinks between LAM resources. NAISC-L supports the linking of related resource across datasets and institutions, thereby enabling richer and more varied search queries, and can thus be used to improve the discoverability of materials held in LAMs.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The semantic web (SW) is an extension of the current Web where data are given well-defined meaning and where the relationships between data, and not just documents, are defined in a common machine-readable format—creating a Web of Data (Berners-Lee et al. 2001). Linked data (LD) describes a set of principles and best practices for publishing, interlinking. and engaging with data on the Semantic Web (Berners-Lee 2006)—these principles include the use of HTTP uniform resource identifiers (URIs)Footnote 1 for naming resources. The use of URIs allows both humans and computers to access information about resources. A LD dataset is structured information encoded using the resource description framework (RDF), the recommended model for representing and exchanging LD (Brickley and Guha 2014). RDF statements take the form of subject–predicate–object triples, which can be organised in graphs and queried using SPARQL (Harris et al. 2013).
LD that is published under an open license is known as linked open data (LOD) (Berners-Lee 2006). LOD is classified according to a Five Star rating system, and to be considered Five Star, a LD dataset must contain interlinks to related data (Berners-Lee 2006; Kim and Hausenblas 2015). The purpose of these LD interlinks is to enhance the knowledge associated with a specific entity (Papaleo et al. 2014). These interlinks have the potential to transform the Web into a globally linked and searchable database, rather than a disparate collection of documents (W3C 2015). Many metadata standards used in libraries, archives, and museums (LAMs) cannot be processed by Web search engines; thus a significant amount of relevant content is not visible in Web search results (Guerrini and Possemato 2016; Pesch and Miller 2016). Metadata published as RDF, however, are easily processed by SW search engines (Schilling 2012)—enhancing data discoverability and visibility. Cross-institutional metadata interlinking would allow for easier, more efficient querying and discovery of LAM materials (Alemu et al. 2012; Coyle 2013; Seeman and Goddard 2015).
Though the number of LAMs publishing LD is growing, upon reviewing prominent existing LAM LD services, see Sect. 2, it was noted that there is a lack of interlinks beyond those that are used for authority control purposes. Authority control describes the use of standardised names for people, corporate bodies, titles, and subjects, known as authority records, as access points in the LAM catalogue—these authority records are held in authority files or controlled vocabularies (Wiederhold and Reeve 2021). As one of the fundamental prerequisites of the SW is the existence of large amounts of meaningfully interlinked resources (Bizer et al. 2009a, b), there is a need to explore how Information Professionals (IPs) can be facilitated to create LD interlinks beyond those used for authority control, so as to fully exploit their domain expertise, specialist subject knowledge, and their understanding of LAM patrons’ needs. As such, the research question investigated in this article is the following: To what extent can NAISC-L, a domain-specific interlinking framework, facilitate Information Professionals to engage with the process of Linked Data interlinking with effectiveness, efficiency and satisfaction?
The major contribution of this research is the interlinking framework—NAISC-L which stands for Novel Authoritative Interlinking for Semantic Web Cataloguing in Libraries and is described in Sect. 4. Unlike existing interlinking frameworks, see Sect. 3, NAISC-L was designed specifically with the needs and work processes of the LAM domain in mind. The NAISC-L framework, described in Sect. 4, is comprised of a Linked Data (LD) interlinking process and accompanying tool. Section 5 details the evaluation of NAISC-L including a think-aloud observation, an online usability test and a field test with the Irish Traditional Music Archive which holds both physical and born-digital materials. The conclusions of the research are discussed in Sect. 6.
2 Background
2.1 Linked data interlinking
LD interlinking describes the task of determining whether a named resource (an entity identified by a URI) can be linked to another named resource in order to indicate that they both describe the same thing or that they are related in some capacity (Ferrara et al. 2011). The purpose of LD interlinks is to provide additional information about an entity in order to improve data discovery (Kim and Hausenblas 2015).
LD interlinks are also known as typed links and the linking property used to describe the relationship between two URIs is known as a link-type (Neubauer 2017). Identity Links are a specific kind of typed-link where the subject and object URI refer to the same entity (Papaleo et al. 2014). Identity links are typically expressed using the owl:sameAs property, from the Web Ontology LanguageFootnote 2 (OWL), and the process of creating these links is referred to as instance matching. The most common type of cross-dataset interlink on the SW are owl:sameAs links (Paris et al. 2019). This property has strict semantics and should only be used where two things are identical and share the same properties (McGuinness and van Harmelen 2004). However, these strict semantics are not always followed leading to the inference of inaccurate data and reducing data quality (De Melo 2013; Halpin et al. 2010; Jaffri et al. 2008; Paris 2018; Raad et al. 2018). These inaccuracies could be reduced by employing Relationship Links—another kind of typed link used to point to related entities in other datasets (Heath and Bizer 2011). Unlike identity links, relationship links do not have to point to exactly the same thing and can thus be used to provide background knowledge and context for an entity.
2.2 Linked data provenance
Data provenance is a record describing the origin of a piece of data and can include information on the date/time, people, institutions, and processes involved in its creation. Given that any individual can publish to the SW, LD provenance is crucial in establishing the trustworthiness and quality of the data (Dezani-Ciancaglini et al. 2012). In the LAM domain, The Open Archival Information System (OAIS) (CCSDS 2019) and Preservation Metadata: Implementation Strategies (PREMIS) (PREMIS Editorial Committee 2015), are both widely accepted standards for digital preservation that require the provision of provenance information when archiving digital resources.
2.3 Linked data services in libraries, archives and museums
In order to ascertain the degree and type of LD interlinking currently being used in the LAM domain, leading LAM LD services and projects were reviewed including the following:
-
1.
The Library of Congress (LOC)Footnote 3 (Summers et al. 2008).
-
2.
LIBRISFootnote 4 (Malmsten 2008, 2009).
-
3.
Europeana ProFootnote 5 (Haslhofer and Isaac 2011).
-
4.
British National Bibliography (BNB)Footnote 6 (Deliot 2014; Deliot et al. 2017).
-
5.
SwissbibFootnote 7 (Bensman et al. 2016).
-
6.
The French National Library (BnF)Footnote 8 (Simon et al. 2013).
-
7.
The Spanish National Library (BNE)Footnote 9 (Vila-Suero and Gómez-Pérez 2013; Vila-Suero et al. 2013).
-
8.
The German National LibraryFootnote 10 (DNB) (Hannemann and Kett 2010).
These LD services have been summarised in Table 1 where it can be seen that, on average, the data was interlinked to five external datasets—primarily authority files and controlled vocabularies as well as datahubs such as DBpediaFootnote 11 and Wikidata.Footnote 12 Although interlinking with authority files and controlled vocabularies is extremely useful, this type of linking predates LD. Additionally, while linking to large-scale datahubs, such as DBpedia and Wikidata, is useful, these datasets do not fall within the LAM domain. Additionally, only two services, Europeana and the BNB, appeared to provide LD provenance information. Finally, the majority of interlinks created by the projects were identity links—leaving vast potential for LAMs to create provenance-rich relationship interlinks that provide additional information and context for a given entity.
3 Related work
3.1 Linked data interlinking tools
The interlinking tools included in this review are those developed for relationship and identity link discovery, and instance matching (Nentwig et al. 2017).Footnote 13 Tools excluded from the review include those developed solely for ontology mapping and vocabulary alignment, as these focus only on the correspondences between vocabularies/schemas. Also, as this research explores the extent to which a domain-specific interlinking framework can facilitate IPs to engage with LD interlinking, the tools were further refined to include only those with a graphical user interface (GUI). The final tools reviewed in Table 2 include:
- 1.
-
2.
LogMap (Jiménez-Ruiz and Grau 2011; Jiménez-Ruiz et al. 2012).
-
3.
LinkItUp (Hoekstra and Groth 2013).
- 4.
-
5.
The LIMES Link Discovery Framework for Metric Spaces (Ngomo and Auer 2011).
-
6.
OpenRefine RDF Extension.Footnote 14
It can be seen that the majority of the tools reviewed were developed solely for instance matching. Only SILK and LIMES allow for the creation of other types of user-specified interlinks. However, in order to create these links, sufficient overlapping information must be available in the dataset. For instance, when one dataset contains only the names of authors and another the names of places, relating authors to place names will thus require external information such as subject matter expertise. As such, there is an evident need to facilitate the creation of interlinks beyond instance matching.
In terms of domain specialisation, only OpenRefine has extensions specifically developed for LAMs. Additionally, none of the reviewed tools has published user-testing data for their GUIs and none publish interlink provenance data. Thus, there is scope for a LD interlinking framework designed specifically for the LAM domain that provides rich data provenance for LD interlinks and that has a user-friendly GUI that has been tested by the tool’s targeted users.
3.2 Linked data requirements survey
Section 3.1 highlighted a need for a LD interlinking framework that facilitates the creation of relationship links. In order to gain a more detailed understanding of this issue, an online LD Requirements Questionnaire was distributed to LAMs. The results of this survey are detailed in McKenna et al. (2018), however a summary has been provided below.
The questionnaire was completed by 185 IPs—representing a variety of LAMs and research institutions including Academic Libraries (56%), Research Institutions (7%), Public Libraries (7%), Special Libraries (6%), Archives (6%), National Libraries (5%), Museums (4%), and Special Archives (1%). Additionally, though not a requirement, most participants had some prior knowledge of LD (90%).
The 50-question survey investigated the following:
-
1.
IPs’ knowledge, views and experience with LD.
-
2.
IPs’ perceived usability of LD tools.
-
3.
Solutions to the LD challenges experienced by IPs.
The key findings of the survey indicated that IPs considered the primary benefits of LD publication and consumption to include the following:
-
1.
Cross institutional linking and integration resulting in additional context for data interpretation and improved cataloguing efficiency.
-
2.
Improved data discoverability and accessibility.
-
3.
Enriched metadata and improved authority control.
The main challenges to LD publication and consumption, as experienced by the survey participants, were as follows:
-
1.
Resource quality issues including LD datasets and URIs not being maintained, a lack of guidelines and use-cases, and difficulty creating and maintaining URIs. Participants also reported that there is insufficient provenance data for LD resources.
-
2.
LD tooling issues including functional inadequacy for the requirements of the library domain, technological complexity, and difficulty integrating into cataloguing workflows. Participants specifically mentioned that tools are often challenging to learn and to use, inadequate for use in LAMs, and difficult to integrate into workflows.
-
3.
Interlinking and integration issues including difficulty with data reconciliation and vocabulary mapping, difficulty selecting appropriate ontologies and link-types when interlinking and difficulty in deciding which datasets to interlink with.
In response to these challenges, the majority of participants (77%) agreed a LD interlinking tool designed specifically for IPs could be useful. The most cited reasons for this being that a bespoke tool could help overcome the technical knowledge gap of IPs, make LD more accessible and increase the number of LAMs using LD—thus providing a strong justification for the development of NAISC-L.
4 The NAISC-L framework
4.1 Design approach
NAISC-L was developed according to a Design Science (DS) approach which is defined as “a research paradigm in which a designer answers questions relevant to human problems via the creation of innovative artefacts, thereby contributing new knowledge to the body of scientific evidence” (Hevner and Chatterjee 2010; Wieringa 2014). Thus, knowledge of and solutions to an identified problem are acquired through the process of iteratively designing, building and testing an artefact (Hevner et al. 2004). This was conducted in line with the principles of User-Centred Design which describes the process of designing a tool in view of how it will be understood and used by users, thus placing the user in the centre of the design process (Lowdermilk 2013; Usability First 2015). These approaches were selected and combined in order to ensure that NAISC-L was developed as a human-centred system (Cooley 1987)—facilitating and enhancing the skills of IPs when generating metadata interlinks, acknowledging that IPs’ domain knowledge and expertise cannot be replaced, only assisted by, technology.
4.2 User requirements
A set of user requirements for the development of a LD interlinking framework for LAMs were distilled from the interlinking tool review and from the results of the LD requirements survey—see Fig. 1.

User requirements for a LD interlinking tool for LAMs
With the above requirements in mind, the NAISC-L Framework was developed. In line with the Design Science Model, NAISC-L was iteratively designed and refined based on the results of three user evaluations described in Sect. 5.
4.3 NAISC-L interlinking process
The NAISC-L interlinking process consists of four cyclical steps, as seen in Fig. 2. These steps are entity selection, link-type selection, provenance data, and RDF graph generation and visualisation.

NAISC-L Interlinking Process
4.3.1 Step 1—entity selection
This step first involves selecting an Internal Entity i.e., an entity from an internal dataset from which an outward link is being created. The URI of the selected entity is then validated by NAISC-L. The user then selects a Related Entity, from an external dataset, to interlink with and its URI is also validated. External dataset quality ratings, for commonly used LAM datasets, are provided to aid in the selection of high-quality resources. The rating is based on three quality metrics—trustworthiness, interoperability and licensing. These metrics were chosen as they were the top three quality criteria used to evaluate external data sources, as selected by participants of the LD Requirements Questionnaire (Debattista et al. 2018). Users also have the option of defining the entities as per the FRBR library reference model (Riva et al. 2016) to aid in link-type selection.
4.3.2 Step 2—link-type selection
Step 2 takes the user through the process of creating an interlink between an internal entity and a related entity. This is done in two stages which are presented to the user via an Interlinking Guide.
The first stage of the Interlinking Guide requires the user to determine the kind of relationship that exists between the entity pair. To do this, the user selects one of six natural language relationship terms—see Fig. 3. Each relationship term is defined and the user should select the definition that most accurately describes the connection between the entity pair. The terms were inspired by the types of identity and similarity links identified by Halpin et al. (2010) in their analysis of owl:sameAs statements on the SW.

Relationship Terms
The second stage of the interlinking guide is to select an appropriate link-type in order to connect the internal entity and the related entity. The link-types presented to the user are narrowed down depending on the Relationship Term selected. The suggested link-types are taken from vocabularies commonly used in LAMs, as identified in the LD Requirements Survey. Other link-types can be pulled directly from Linked Open VocabulariesFootnote 15 (LOV).
4.3.3 Step 3—provenance data
Provenance data describing by whom, where, when and how an interlink was created is automatically generated by NAISC-L. With regard to ‘why’ an interlink was created, this justification datum is manually supplied by the user after selecting a link-type. This justification can include, but is not limited to, a description of the relationship between the entities, the purpose of the interlink, the interlink context and the rationale behind the chosen link-type. The data are structured as per the NAISC-L Provenance Data Model, described below in Sect. 4.4.2.
4.3.4 Step 4—RDF graph generation and visualisation
NAISC-L data is stored in a relational database (RDB) and is uplifted to RDF using R2RML, a W3C Recommendation used to express mappings from RDBs to RDF (Das et al. 2012). NAISC-L’s Knowledge Organisation, detailed in Sect. 4.4.1, consists of three named graphs—an interlink graph, a provenance graph and a relationship graph. The data for each graph are uplifted to RDF using a separate R2RML mapping. These mappings were created using the JUMA mapping tool (Crotti et al. 2018). The graphs can be viewed and downloaded in different RDF serialisation formats. The graphs can also be explored via interactive visualisations generated using GoJS.Footnote 16
4.4 NAISC-L tool
The NAISC-L Tool consists of an approach to knowledge organisation, a provenance data model and a GUI, all of which are detailed below.
4.4.1 NAISC-L knowledge organisation
NAISC-L’s knowledge organisation, Fig. 4, comprises of three named graphs—an interlink graph, a provenance graph and a relationship graph. A named graph is an RDF sub-graph containing a set of triples that has been assigned a unique name in the form of a URI (Carroll et al. 2005). These collections of triples can then be published as independent units. Separating the data across the three graphs simplifies some of the queries that users can formulate and run over the data, while still allowing for queries that span across graphs, as facilitated by the relationship layer.

NAISC-L Knowledge Organisation
-
1.
Interlink graph: This is a named graph containing a collection of interlinks known as a linkset. When changes are made to the linkset in NAISC-L, these changes are reflected in the Interlink Graph once an interlinking session is complete. Interlinking sessions are controlled by NAISC-L users and are completed when users actively update the Interlink Graph with the additions, deletions or revisions they have made to the linkset. A linkset has only one named graph that contains all of its active interlinks. This design allows for simple and efficient querying of the interlinks.
-
2.
Provenance graph: This is a named graph, in the form of a prov:Bundle, that contains the provenance data of the links in an Interlink Graph. Multiple provenance graphs can be associated with one Interlink Graph, as a new provenance graph is created for every interlinking session. A Provenance Graph contains the origin data of the interlinks created during an interlinking session, as well as the origin data for the linkset itself. It also provides a history of the interlink deletion and revision activities that occurred during an interlinking session. These descriptions are provided using RDF Reification (Manola and Miller 2004).
-
3.
Relationship graph: This is a named graph containing a set of statements linking an Interlink Graph with its Provenance Graphs using the property prov:has_Provenance. This property, which is part of PROV-AQ: Provenance Access and QueryFootnote 17 (Moreau et al. 2013), specifies how to obtain a provenance record associated with a resource.
4.4.2 NAISC-L provenance data model
The NAISC-L provenance data model, described in detail in McKenna et al. (2019a), is based on the PROV Data Model—a Web-Oriented provenance standard, developed by the W3C Provenance Working Group, for the representation and exchange of provenance information (Belhajjame et al. 2013). The PROV Ontology (PROV-O) is an OWL ontology that maps the PROV Data Model to RDF. PROV-O was used as part of the NAISC-L Provenance Data Model because it is a W3C-recommended standard and because it can be easily extended for domain-specific purposes. Existing PROV-O classes, sub-classes and properties were used to describe by whom, where, when and how interlinks were created. PROV-O was extended in order to describe why an interlink was created, and to provide additional details on how it was created. This extension, called NaiscProv, includes the addition of interlink specific subclasses and properties—see Fig. 5. Figure 6 displays how the provenance model is used to describe the creation of an interlink.

PROV-O Extension—NaiscProv

Provenance for the creation of an interlink
4.4.3 NAISC-L graphical user interface
The final component of the NAISC-L tool is the GUI—a demo of which can be viewed online.Footnote 18 In line with the Design Cycle of the Design Science Model, the GUI was iteratively designed, testing and refined based on the results of the user evaluations discussed in Sect. 5. NAISC-L was built using Apache Tapestry,Footnote 19 a component-oriented framework for creating web applications in Java, BootstrapFootnote 20 CSS library, and a MySQLFootnote 21 database. Other, previously mentioned, technologies also used as part of the framework included R2RML (RDB to RDF mapping) and GoJS (data visualisation).
The GUI is an instantiation of the NAISC-L framework developed to guide IPs through the interlinking process, as seen in Figs. 7, 8, 9, 10, 11, 12 and 13.

NAISC-L GUI—Homepage

NAISC-L GUI—Entity Selection

NAISC-L GUI—Relationship Selection

NAISC-L GUI—Link-type Selection

NAISC-L GUI—Provenance Data

NAISC-L GUI—Interlink Graph GoJS Visualisation

Interlink RDF output
5 Evaluation
Three usability tests were conducted in order to evaluate NAISC-L—a think-aloud test, an online interlink creation test and a field test. In this section, the findings of all three experiments are presented to answer the research question. As Usability Test 1, the think-aloud test has been partly published in McKenna et al. (2019b), the finding for this experiment have been summarised. As per the DS approach, the results of the experiments were used to iteratively design, develop and improve NAISC-L.
5.1 Evaluation instruments
Common instruments used across the usability tests included the following:
5.1.1 Pre-test questionnaire
A pre-test questionnaire was developed to ascertain participants’ knowledge and experience with LD prior to partaking in an experiment. Participants were asked to rate their knowledge on a five-point Likert scale ranging from ‘Not at all Knowledgeable’ to ‘Extremely Knowledgeable’. The pre-test questionnaire was used as part of all usability tests.
5.1.2 Post-test interview
Interviews were conducted as part of Usability Test 1 and Usability Test 3 in order to gain an insight into the participants’ experience of using NAISC-L—see Fig. 14 for the interview questions.

Interview questions
5.1.3 Usability questionnaire
The Post-Study System Usability Questionnaire (PSSUQ) (Lewis 1992, 2002) was used as part of Usability Test 1 and Usability Test 2. The PSSUQ is used to measure system usability at the end of a scenario-based user-study and consists of 19 positive items about which the user rates agreement on a seven-point Likert scale from Strongly Agree (1) to Strongly Disagree (7), Responses can be calculated to provide an overall usability score as well as scores for three subscales including:
-
System usefulness—Items 1–8 (SysUse).
-
Information quality—Items 9–15 (InfoQual).
-
Interface quality—Items 16–18 (InterQual).
-
Overall—Items 1–19.
It is important to note that lower PSSUQ scores indicate a more positive user perception of the questionnaire items.
The Computer System Usability Questionnaire (CSUQ) (Lewis 1995) was used as part of the Usability Test 3. The CSUQ is used for measuring system usability and utility as part of a survey or during field research. It is almost identical to the PSSUQ except for some small differences in item wording.
5.1.4 Data quality questionnaire
Data quality (DQ) is defined as the fitness for use of data for given application or use-case, and it is often measured according to a set of dimensions such as accessibility, trustworthiness and completeness (Zaveri et al. 2016). A modified version of the AIM Quality (AIMQ) questionnaire (Lee et al. 2002) was used in order for participants to evaluate the quality of the data they created using NAISC-L during Usability Test 2. The AIMQ questionnaire consists of 65 statements regarding DQ about which the user rates their level of agreement on a scale of 0 (disagree) to 10 (agree). In terms of scoring, higher ratings indicate a more positive perception of the statements. For the purpose of this research, a subset of 25 statementsFootnote 22 was used to evaluate the DQ of NAISC-L output. It was decided to modify the questionnaire in order to reduce its completion time.
5.1.5 Thematic analysis
Audio recordings from Usability Test 1 and Usability Test 3 were evaluated using thematic analyses on N-Vivo 12Footnote 23 qualitative data analysis software. “Thematic analysis is a method for identifying, analysing, and reporting patterns within data” (Braun and Clarke 2006, p. 79). It involves the systematic break down of data derived from qualitative research into codes, or categories, and discovering common themes by analysing and combining them. It is a method often used for the analysis of user-study data (Rosala 2019).
5.2 Usability test 1
The focus of this user experiment was to evaluate the usability and utility of NAISC-L. Usability Test 1 consisted of a think-aloud test, a post-test interview and the PSSUQ—the results of which are summarised below. The experiment has been described in detail in McKenna et al. (2019b).
5.2.1 Summary
Usability test 1 was completed by 15 IPs—13 considered themselves to be ‘Moderately Knowledgeable’ in LD and two considered themselves ‘Slightly Knowledgeable’. Seven worked in academic libraries, three in a national library, two in a museum, two in a music archive and one in a government library.
As part of this experiment the participants completed a think-aloud test (TAT) which required them to verbalise their thoughts while carrying out six scenario-based tasks on NAISC-L, thus providing data on the types of difficulties they encountered and highlighting areas of the framework that required further improvement (Becker and Yannotta 2013; van den Haak et al. 2003). The scenario of the TAT was that of a cataloguer creating interlinks from entities in the BnF to related entities in other LD datasets. The six TAT tasks required participants to engage with all four steps of the interlinking process in order to create six interlinks. Upon finishing the TAT, participants completed the post-test interview and the PSSUQ.
The hypothesis being investigated as part of this experiment is stated as follows:
Hypothesis 1.1 (H1.1)
Using the NAISC-L Framework to create LD interlinks yields high task performance with sufficient usability for IPs.
Performance above 83%, for both the number of interlinks completed and their semantic accuracy, was considered to be high, given a score of 83% indicated that participants completed an average of 5 out of 6 interlinks accurately. Usability was measured using the PSSUQ and ‘sufficient usability’ was considered to be scores strictly lower than a neutral score of 4, as lower scores indicate more positive perceptions of the questionnaire items.
In the TAT, participants were, on average, 95.55% successful in completing all six interlinks and 91.12% successful in selecting a semantically accurate link-type, indicating high performance (above 83%) for both completeness and accuracy. In the PSSUQ (see Tables 3, 4), the mean score for each item, as well as for the SysUse, InfoQual, InterQual and Overall scores, was lower than 4, indicating that sufficient usability was achieved. The experiment confirmed H1.1 indicating that IPs can use NAISC-L for the creation of LD interlinks with high performance and sufficient usability.
In addition to the above, three rounds of thematic analysis were conducted on the TAT recordings and the post-test interview data leading to the identification of five themes with a combined 33 associated codes—see Table 5. Overall, participants had a positive reaction to the NAISC-L interlinking process, finding it usable, useful and user-friendly. Some suggestions were made, such as increased automation and changes to the GUI, in order to make the tool more efficient and to increase usability.
5.3 Usability test 2
The focus of this experiment was to evaluate the usability and utility of NAISC-L, and to evaluate the quality of the data created using framework. Usability Test 2 consisted of an interlink creation test (ICT), the PSSUQ and the Data Quality (DQ) Questionnaire.
5.3.1 Hypotheses
The hypotheses being investigated as part of this experiment are as follows:
-
Hypothesis 2.1 (H2.1): Using the NAISC-L Framework to create LD interlinks yields high task performance with sufficient usability and sufficient data quality for IPs.
-
Hypothesis 2.2 (H2.2): The number of interlinks completed is higher for participants who used the NAISC-L Interlinking Guide when compared to participants who did not use the Interlinking Guide.
-
Hypothesis 2.3 (H2.3): Interlink accuracy is higher for participants who used the NAISC-L Interlinking Guide when compared to participants who did not use the Interlinking Guide.
-
Hypothesis 2.4 (H2.4): PSSUQ scores are better for participants who used the NAISC-L Interlinking Guide when compared to participants who did not use the Interlinking Guide.
-
Hypothesis 2.5 (H2.5): Data Quality perceptions are better for participants who had access to the Interlink Provenance Output RDF Graph and Visualisation when compared to participants who did not have access to the provenance output.
Task performance and usability were evaluated via the ICT. Task performance above 66%, for both the number of interlinks completed and interlink accuracy, was considered to be high as a score of 66% indicated that participants completed an average of 2 out of 3 interlinks accurately. Usability was measured using the PSSUQ and DQ was evaluated using the DQ Questionnaire. In this experiment, ‘sufficient usability’ was considered to be scores strictly lower than a neutral score of 4. As stated previously, lower PSSUQ values indicate more positive perceptions of a system. ‘Sufficient data quality’ was considered to be scores above 5, as higher values in the DQ questionnaire indicate more favourable perceptions.
5.3.2 Participants
Non-probabilistic sampling methods were used to recruit the participants for this study whereby LAMs were contacted directly with a description of the research and a link to the survey to distribute to staff. The experiment was completed online by 96 IPs from varying LAM backgrounds. Prior to completing the ICT, participants first completed the pre-test questionnaire. An inclusion criterion for the experiment was that participants must have some knowledge of LD, as such 18% rated themselves as ‘Slightly Knowledgeable’, 36% as ‘Moderately Knowledgeable’, 32% as ‘Very Knowledgeable’ and 14% as ‘Extremely Knowledgeable’.
5.3.3 Interlink creation test
The interlink creation test (ICT) required participants to create the same three interlinks using NAISC-L. The scenario of the ICT was the same as the TAT i.e. a cataloguer creating interlinks from entities in the BnF to related external entities. Prior to completing the ICT, participants were randomly split into four user groups and presented with a different version of NAISC-L depending on this group. Versions either included or excluded the Interlinking Guide and/or the provenance RDF graph and visualisations—see Table 6. This versioning was done in order to compare participants’ user experience, interlink accuracy, interlink completion, and DQ perception depending on the level of guidance and provenance information they were presented with. There was no statistically significant difference between participants’ prior LD Knowledge ratings across the four groups as determined by Kruskal–Wallis Test (χ2(2) = 0.914, p = 0.822) and a One-Way ANOVA (F(3,92) = 0.357, p = 0.784).
The ICT was followed by the PSSUQ and the DQ questionnaire. All components of this test were conducted online.
5.3.4 Findings
5.3.4.1 Interlink creation test
Table 7 provides the average number of interlinks completed across the four groups. Participants had to create three links, hence possible values for the average are within the range \([\mathrm{0,3}]\subseteq \mathcal{R}\). High task performance was achieved across all groups as the average number of interlinks created was above 66%.
5.3.4.2 Interlink accuracy
Table 8 below provides the average interlink accuracy scores across the four groups. These scores are based on how successful participants were in choosing a reasonable and semantically accurate link-type to represent the relationship between each pair of entities. For the purpose of this research, a reasonable link-type was considered to be a predicate that, according to its ontological definition, could be used to meaningfully link the given entities. Again, the average score lies within the range \(\left[\mathrm{0,3}\right]\subseteq \mathcal{R}\). High task performance was achieved only by Group A and Group C as both had an average accuracy score above 66%. Both these groups conducted the ICT using a version of NAISC-L which included the Interlinking Guide.
5.3.4.3 PSSUQ
The PSSUQ was used to evaluate the usability of each version of NAISC-L. Table 9 shows the average (AVG) scores and standard deviation (SD) per group. It can be seen that sufficient usability was achieved in all areas for all groups as their average scores were less than 4. The groups with the lowest average scores were Group A and Group C, both of which included the Interlinking Guide—note that lower PSSUQ scores indicate a more positive perception of the questionnaire items.
5.3.4.4 Data quality
The DQ questionnaire was used to evaluate the perceived DQ of the interlink output from each version of NAISC-L. Table 10 shows the average scores and standard deviation (SD) per group. It can be seen that sufficient data quality was achieved for all groups as all had average scores greater than 5.
5.3.5 Discussion
Five hypotheses were investigated as part of Usability Test 2. The first was H2.1 which stated that ‘using the NAISC-L Framework to create LD interlinks yields high task performance with sufficient usability and sufficient DQ for IPs’. Here ‘high task performance’ was achieved if 66% of interlinks were completed with 66% semantic accuracy, ‘sufficient usability’ was achieved if PSSUQ scores were lower than 4 and ‘sufficient DQ’ was achieved for DQ questionnaire scores above 5.
In the ICT, the mean number of interlinks completed and the mean interlink semantic accuracy score was above 66%. This indicates that high task performance was achieved for the creation of interlinks using the NAISC-L framework regardless of which version participants used. Similarly, the average SysUse, InfoQual, InterQual and Overall PSSUQ scores across all groups was less than 4, indicating that sufficient usability was achieved for all groups using the NAISC-L framework. Finally, the average overall DQ score for each group was above 5, indicating that sufficient DQ was achieved for all groups using the NAISC-L framework.
Overall, the experiment indicated that IPs can use NAISC-L for the creation of LD interlinks with high performance, sufficient usability and sufficient DQ—confirming H2.1 of this experiment. Interestingly, H2.1 was accepted for all versions of NAISC-L.
H2.2 of this experiment investigated whether ‘the number of interlinks completed is higher for participants who used the NAISC-L Interlinking Guide when compared to participants who did not used the Interlinking Guide’. There was no statistically significant difference between the average number of interlinks created across each of the four groups as determined by a Kruskal–Wallis test (Kruskal and Wallis 1952) (χ2(2) = 1.512, p = 0.680) and a one-way ANOVA (Fisher 1919) (F(3,92) = 0.728, p = 0.538). Similarly, there was also no significant difference between the number of interlinks created by the interlinking guide (IG) group (Group A + Group C) and the non-interlinking guide (NIG) group (Group B + Group D) as determined by a Mann–Whitney U test (Mann and Whitney, 1947) (U = 1106.5, p = 0.664) and an independent-samples T-test (Student 1908) (t = 0.379, p = 0.706).
Additionally, there was no statistical correlation found between perceived LD knowledge and the number of interlinks completed for Group B, Group C and Group D. This indicates that these participants were able to create a similar number of interlinks regardless of prior LD knowledge. However, there was a correlation found between the number of interlinks created and perceived LD knowledge for Group A as determined by the Pearson (Pearson 1895) (r = − 0.462, p = 0.026) and the Spearman (Spearman 1904) (rs = − 0.518, p = 0.011) correlation tests. This is despite the fact that there was no statistically significant difference found between the perceived LD Knowledge ratings of the groups.
Overall, the experiment indicated that the number of interlinks completed is not higher for participants who used the NAISC-L Interlinking Guide when compared to participants who did not use the Interlinking Guide—leading to the rejection of H2.2.
H2.3 of this experiment investigated whether ‘interlink semantic accuracy is higher for participants who used the NAISC-L Interlinking Guide when compared to participants who did not use the Interlinking Guide’. On analysis of the data, it was found that there was a statistically significant difference between the accuracy scores of each the four groups as determined by the Kruskal–Wallis H test (χ2(2) = 26.822, p = 0.000) and a one-way ANOVA (F(3,92) = 12.138, p = 0.000).
A Tukey posthoc test (Tukey, 1949) revealed that interlink accuracy was statistically significantly higher for Group A (2.13 ± 0.81 interlinks, p = 0.002) and Group C (2.09 ± 1.19 interlinks, p = 0.004) when compared to Group B (1.12 ± 0.81 interlinks). The Tukey posthoc test also revealed that interlink accuracy was statistically significantly higher for Group A (2.13 ± 0.81 interlinks, p = 0.000) and Group C (2.09 ± 1.19 interlinks, p = 0.000) when compared to Group D (0.80 ± 0.89 interlinks). Note that both Group A and Group C used the Interlinking Guide whereas Group B and D did not. When the scores of the groups were combined to form an IG group (Group A + Group C) and an NIG group (Group B + Group D), the accuracy scores of the IG group were found to be statistically significantly higher than those of the NIG group as determined by a Mann–Whitney U test (U = 482, p = 0.000) and an Independent-Samples T test (t = 5.937, p = 0.000).
In addition, no correlation between perceived LD knowledge and interlinking accuracy was found. This indicates that participants were able to create interlinks with similar levels of accuracy regardless of prior LD knowledge.
Overall, the experiment indicated that interlink accuracy is higher for participants who used the NAISC-L Interlinking Guide when compared to participants who did not use the Interlinking Guide—leading to the confirmation of H2.3.
H2.4 of this experiment investigated whether ‘PSSUQ scores are better for participants who used the NAISC-L Interlinking Guide when compared to participants who did not use the Interlinking Guide’. On comparison of the SysUse, InfoQual, InterQual and Overall PSSUQ scores between all groups, it was found that there was no statistically significant difference between the scores of each group.
However, when the PSSUQ scores of the groups were combined to form an IG group (Group A + Group C) and an NIG group (Group B + Group D), it was found that the InfoQual score was statistically significantly lower for the IG group than the NIG group as determined by a Mann–Whitney U test (U = 779.5, p = 0.007) and an independent-samples T test t = − 2.791, p = 0.006). It was also found that the Overall scores were statistically significantly lower for the IG group than the NIG group as determined by a Mann–Whitney U test (U = 849.5, p = 0.029) and an Independent-Samples T test (t = − 2.253, p = 0.027). As lower scores in the PSSUQ indicate more favourable perceptions, it can be concluded that participants who used the Interlinking Guide perceived better overall usability and utility for NAISC-L when compared to participants who did not use the Interlinking Guide.
In sum, results indicated that InfoQual and Overall PSSUQ scores are better for participants who used the NAISC-L Interlinking Guide when compared to participants who did not use the Interlinking Guide—confirming H2.4.
H2.5 of this experiment investigated whether ‘DQ perceptions are better for participants who had access to the Interlink Provenance Output RDF Graph and Visualisation when compared to participants who did not have access to the provenance output’. On comparison of the DQ scores between all groups, it was found that there was no statistically significant difference between them as determined by the Kruskal–Wallis H test (χ2(2) = 1.680, p = 0.641) and a One-Way ANOVA (F(3,92) = 0.731, p = 0.2536). Similarly, when the DQ scores of the groups were combined to form a provenance output (PO) group (Group A + Group B) and a no provenance output (NPO) group (Group C + Group D), it was again found that there was no statistically significant difference between the groups as determined by a Mann–Whitney U test (U = 1062.5, p = 0.754) and an independent-samples T test (t = − 0.509, p = 0.612).
Overall, the experiment indicated that DQ scores are not better for participants who had access to the Interlink Provenance Output RDF Graph and Visualisation when compared to participants who did not have access to the provenance output—leading to the rejection of H2.5.
In sum, participants across all groups had a positive response to NAISC-L, as indicated by the PSSUQ and DQ questionnaire results. Notably, participants who used NAISC-L Version A, the version which included both the Interlink Guide and the provenance output, had high semantic accuracy and high interlink completeness scores. This group also had better PSSUQ scores when compared to versions of NAISC-L which did not include the Interlink Guide. The presence or absence of the provenance output did not seem to have a significant impact on perceptions of DQ.
5.4 Usability test 3
A Field Test was conducted in order to evaluate the use of NAISC-L in a real information environment. The experiment was completed by three IPs working in a music archive and consisted of a field test, a post-test interview and the CSUQ.
5.4.1 Hypothesis
The hypothesis being investigated as part of this experiment are as follows:
-
Hypothesis 3.1 (H3.1): Using the NAISC-L Framework, in a LAM context, to create LD interlinks from an institution’s dataset yields high accuracy with sufficient usability for IPs.
Accuracy and usability were evaluated via a field test. For the purpose of this experiment, interlink accuracy above 75% was considered to be high. Usability was also measured using the CSUQ. In this experiment, ‘sufficient usability’ was considered to be scores strictly lower than a neutral score of 4. As stated previously, lower CSUQ values indicate a better perception of a system.
5.4.2 Participants
For this experiment, NAISC-L was evaluated in the context of the Irish Traditional Music ArchiveFootnote 24 (ITMA). ITMA holds a vast collection of both physical and born-digital materials relating to Irish traditional music, songs and dance. ITMA was recently involved in the LITMUSFootnote 25 (Linked Irish Traditional Music) project which focused on the development of the first LD framework tailored to the needs of Irish traditional song, instrumental music and dance. The project included the development of the LITMUS ontology to represent contemporary and historical Irish traditional music practice, documentation and performance, as well as a LD pilot project. This project involved using 20 years of TG4 Gradam CeoilFootnote 26 (Irish traditional music awards) performance data in order to create a LD dataset that demonstrated the use of the LITMUS ontology and vocabularies.
Three IPs working at the archive volunteered to participate in the field test. The pre-test questionnaire results indicated that all participants considered themselves ‘Moderately Knowledgeable’ of LD. Additionally, one participant indicated that they had previous experience implementing a LD project. Literature indicates that three participants can discover approximately 65% of issues (Virzi, 1992; Nielsen and Landauer 1993), including the majority of the most significant problems (Krug 2014).
5.4.3 Field test
Field Tests are research activities conducted in the user’s context (Farrell 2016). This approach was chosen as testing under realistic conditions can capture information and reveal issues that may not arise in an artificial environment. The method used for this field test was a diary study whereby participants maintained a log in which they documented comments on their experience of using NAISC-L in real-time. This was then followed up with a post-test interview and CSUQ in order to gain further insight into the users’ experience.
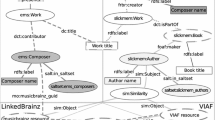
Over one working week, the three IPs at ITMA used NAISC-L for a short period each day in order to create a set of interlinks. These interlinks connected some of the musicians and bands referenced in TG4 Gradam Ceoil LD dataset to related entities in VIAF, the OCLC-hosted name authority service. The aim of these interlinks was to provide authoritative information for specific individuals or groups, as well as to link to other LAMs that contributed to a VIAF record.
5.4.4 Results
5.4.4.1 Field test
A total of 34 interlinks were created by the participants over the course of a week. These interlinks were all owl:sameAs links from ITMA’s TG4 Gradam Ceoil data to VIAF (27 interlinks), Library of Congress (LOC) (5 interlinks), the German National Library (DNB) (1 interlink), French National Library (BNF) (1 interlink). It is worthy of note that the participants of the field-test consciously decided to use NAISC-L to specifically create only links of type owl:sameAs as this was a real task that they wished to perform on the TG4 dataset that they were not able to complete previously due to a lack of appropriate tooling. Despite using the same link-type throughout, participants nevertheless gained a full experience of the interlinking process.
All participants had an interlink accuracy score of 100% meaning that high accuracy (over 75%) was achieved. Although it was decided by the participants to create only owl:sameAs interlinks, measuring the accuracy is still useful as accuracy is dependent on both the selected link-type and the chosen external entity. In this case, the external entity of each interlink was verified to be identical to its internal entity.
5.4.4.2 Thematic analysis: field test diary and interviews
Three rounds of thematic analysis were conducted on the field test diaries and post-test interview data resulting in the generation of 30 codes. It was found that the 30 codes could be grouped according to the themes which emerged from Usability test 1. These themes and codes are detailed in Table 11.
Theme 1 and Theme 2 relate to the usability and utility of the interlinking process and the provenance data. Codes for Theme 1 indicate that participants found NAISC-L to be useful, user-friendly and straightforward. Participants also found the provenance data to be useful and that it added authority to the interlinks.
A number of new requirements for NAISC-L were distilled from the experiment data. The codes in Theme 3 indicate a need to simplify the link-type definitions used in NASIC-L and to provide more precise descriptions for the data that should be entered into entity description and justification fields. Codes in Theme 4 highlight new requirements for the GUI such as fixing a URI validator error, adding copy buttons to entity labels, pre-populating related entity data fields with data from the internal entity, and pre-populating the justification field with data from the related entity description. Similar to Usability Test 1, Theme 5 relates to suggestions automating some of the NAISC-L processes in order to reduce the time it takes to create an interlink. Suggestions included automatically searching a dataset for a related entity and, once an entity is selected, auto-populating the appropriate data fields.
5.4.4.3 CSUQ
As mentioned, the CSUQ items are scored from 1 to 7 with lower scores indicating more positive perceptions. For the purpose of this experiment, sufficient usability was considered to be scores lower than 4. The CSUQ scores for each participant and the mean scores for each item can be found in Tables 12 and 13. It can be seen that the mean score for each item, except for Item 9, is below 4 indicating that participants were generally in agreement with the CSUQ items and that sufficient usability was achieved for almost all items. However, Item 9, which reads, “The system gave error messages that clearly told me how to fix problems”, had a mean score of 5 signifying more negative perceptions of this item. The reason behind this negative perception was distilled from the interview data where participants indicated that there was an intermittent error with the URI validator which they were unable to resolve.
The mean SysUse, InfoQual and InterQual subscale scores, as well as the mean Overall score, can also be found in Table 13. The mean scores for the SysUse and InterQual were less than 3, indicating mostly positive perceptions of their items. The mean InfoQual and Overall scores were 3.19 and 3.22, respectively, indicating some mixed responses to items. All mean scores were less than 4, signifying that sufficient usability was achieved for the Field Test and suggesting only mild usability and utility issues overall.
5.4.5 Discussion
The hypothesis (H3.1) being investigated as part of the Field Test was whether ‘using the NAISC-L Framework, in a LAM context, to create LD interlinks from an institution’s dataset yields high accuracy with sufficient usability for IPs’. Here ‘high accuracy’ was considered to be interlinks with over 75% accuracy, and ‘sufficient usability’ to be CSUQ scores strictly lower than a neutral score of 4.
In the Field Test, the mean accuracy score for all participants was above 75%. This indicates high accuracy for the creation of interlinks using the NAISC-L framework. The mean SysUse, InfoQual, InterQual subscale scores and the mean Overall score, were all lower than 4 indicating that sufficient usability was achieved for IPs when using NAISC-L.
In sum, the experiment indicated that IPs, in a LAM context, can use NAISC-L for the creation of LD interlinks with high accuracy and sufficient usability—confirming the hypothesis (H3.1) of this experiment.
Overall, participants had a positive reaction to the flow of the NAISC-L framework and stated that it was useful and user-friendly. This suggests that NAISC-L is both effective and satisfactory. The new requirements distilled from the data were primarily suggestions for automating certain steps and adding extra functions to the GUI in order to make the interlinking process more time efficient.
6 Conclusion
LD provides a means for LAMs to expose both physical and digital resources to a larger community of potential users, however, LD interlinking has been identified as a key challenge for IPs. In order to address this gap, this article investigated, ‘To what extent can NAISC-L, a domain-specific interlinking framework, facilitate IPs to engage with the process of LD interlinking with effectiveness, efficiency and satisfaction?’. NAISC-L was found to be effective, efficient and to have high user satisfaction as indicated by:
-
High interlink accuracy and completeness across all three experiments indicating that IPs, with varying levels of LD knowledge, could effectively use the NAISC-L to create LD interlinks.
-
The mean SysUse PSSUQ/CSUQ scores, measuring effectiveness and efficiency, were lower than 4 across all experiments indicating that participants had mostly positive perceptions of these items. That said, the thematic analysis of Usability Test 1 and Usability Test 3 did indicate that participants found the interlinking process to be time-consuming and that certain functions could be automated in order to save time. While increased automation would improve efficiency, it would be important to ensure a balance between automatic and manual processes as increased automation has the potential to detract from the contextually rich interlinks created manually by domain expert IPs.
-
The mean InterQual and Overall PSSUQ/CSUQ scores, measuring user satisfaction, were lower than 4 across all three experiments indicating mostly positive perceptions of these items. Furthermore, in Usability Test 1 and Usability Test 3, the thematic analysis revealed that participants considered the NAISC-L interlinking process to be useful, straightforward and intuitive. Participants also found the NAISC-L tool to be user-friendly, clear and suitable for non-expert LD users.
NAISC-L advances the state-of-the-art by presenting an interlinking framework that facilitates the creation of relationship and identity links, and that is accessible via a GUI designed to support IPs. It is envisaged that the NAISC-L framework will have an impact on the adoption of LD in LAMs by facilitating IPs to create LD interlinks with greater ease and efficacy than existing LD tooling allows. NAISC-L is complementary to existing interlinking frameworks as it supports the creation of relationship links through an interlinking process that encourages the application of domain expert knowledge. Facilitating the application of domain expertise allows IPs to use their specialist knowledge of particular subject areas, as well as their tacit knowledge of the needs and interests of LAM users, for the creation of useful, interesting and creative interlinks. Additionally, the provision of provenance data, detailing IPs as the creators and curators of these interlinks, increases user trustworthiness. In sum, LAM metadata that has been enriched with authoritative interlinks, created by IPs, would improve data discovery and promote increased use of LAM resources by allowing users to navigate seamlessly between related entities held in internal and external datasets.
Availability of data and materials
Materials used as part of this research include: The Post-Study System Usability Questionnaire (PSSUQ) (Lewis 1992, 2002) and the Computer System Usability Questionnaire (CSUQ) (Lewis, 1995). A Linked Data Questionnaire (Linked Data Questionnaire—http://hdl.handle.net/2262/82671 accessed May 8th 2021), developed by the researcher, and a Modified AIM Quality (AIMQ) questionnaire (Modified AIMQ Questionnaire http://hdl.handle.net/2262/96220 accessed 13th May 2021) (Lee et al. 2002) both of which are available on Trinity’s Access to Research Archive (TARA). The raw research data is not publicly available.
Code availability
The code for NAISC-L is not publicly available. However, there is a NAISC-L demo (NAISC-L Demo—https://www.scss.tcd.ie/~mckennl3/naisc/ and https://libguides.tcd.ie/libtech2019/naisc accessed August 30th 2021) available online and researchers can contact the authors should they wish to use NAISC-L.
Notes
Note that uniform resource identifiers (URIs) have been superseded by International Resource Identifiers (IRIs), which extend URIs with international characters. In the context of this paper, URIs and IRIs both refer to identifiers for resources (documents, entities, etc.) and can be used interchangeably. The term URI is used in this article as this was the term that appeared more frequently in the related work.
https://www.w3.org/TR/owl-overview/ accessed 27th July 2020.
http://id.loc.gov accessed 11th July 2020.
http://libris.kb.se data accessed 30th July 2020.
https://pro.europeana.eu/page/linked-open-data accessed 30th July 2020.
http://bnb.data.bl.uk accessed 18th July 2020.
https://data.swissbib.ch/ accessed 30th July 2020.
https://data.bnf.fr/en/about accessed 9th May 2021.
http://datos.bne.es/inicio.html accessed 30th July 2020.
https://www.dnb.de/DE/Home/home_node.html accessed 30th July 2020.
https://wiki.dbpedia.org/ accessed 9th August 2020.
https://www.wikidata.org/wiki/Wikidata:Main_Page accessed 16th July 2020.
Also known as entity resolution.
https://openrefine.org/ accessed 16th July 2020.
https://lov.linkeddata.es/dataset/lov/ accessed 3rd August 2020.
https://www.nwoods.com/products/gojs/index.html accessed August 3rd 2020.
https://www.w3.org/TR/prov-aq/ accessed 18th August 2020.
NAISC-L Demo—https://www.scss.tcd.ie/~mckennl3/naisc/ and https://libguides.tcd.ie/libtech2019/naisc accessed August 30th 2021.
https://tapestry.apache.org/ accessed 16th August 2020.
https://getbootstrap.com/ accessed 26th August 2020.
https://www.mysql.com/ accessed 16th August 2020.
Modified AIMQ Questionnaire http://hdl.handle.net/2262/96220 accessed 13th May 2021.
https://www.qsrinternational.com/nvivo-qualitative-data-analysis-software/home accessed 12th August 2020.
https://www.itma.ie/ accessed July 20th 2020.
https://www.itma.ie/litmus/info accessed July 20th 2020.
References
Alemu G, Stevens B, Ross P, Chandler J (2012) Linked Data for libraries: benefits of a conceptual shift from library-specific record structures to RDF-based data models. New Library World 113(11/12):549–570. https://doi.org/10.1108/03074801211282920
Becker DA, Yannotta L (2013) Modeling a library web site redesign process: developing a user-centered web site through usability testing. Inf Technol Libr 32(1):6–22. https://doi.org/10.6017/ital.v32i1.2311
Belhajjame K, Cheney J, Corsar D, Garijo D, Soiland-Reyes S, Zednik S, Zhao J (2013) PROV-O: the PROV ontology. https://www.w3.org/TR/prov-o/
Bensman F, Prongu N, Hellstern M, Kuntschik P (2016) Swissbib goes linked data. Paper presented at Semantic Web in Libraries (SWIB) 2016.
Berners-Lee T, Hendler J, Lassila O (2001) The semantic web. Sci Am 284(5):34–43
Berners-Lee T (2006) Linked data. www.w3.org/DesignIssues/LinkedData.html
Bizer C, Volz J, Kobilarov G, Gaedke M (2009b) Silk—a link discovery framework for the web of data. CEUR Workshop Proceedings 538:1–6
Bizer C, Heath T, Berners-Lee T (2009) Linked data: the story so far. Int J Semant Web Inf Syst (IJSWIS) 5(3):1–22. https://doi.org/10.4018/jswis.2009081901
Braun V, Clarke V (2006) Using thematic analysis in psychology. Qual Res Psychol 3(2):77–101. https://doi.org/10.1191/1478088706qp063oa
Brickley D, Guha RV (2014) RDF Schema 1.1. https://www.w3.org/TR/rdf-schema/
Carroll JJ, Bizer C, Hayes P, Stickler P (2005) Named graphs. J Web Semant 3(4):247–267. https://doi.org/10.1016/j.websem.2005.09.001
Consultative Committee for Space Data Systems (CCSDS) (2019) Reference model for an open archival information system (OAIS). http://www.oais.info/
Cooley M (1987) Human centred systems: an urgent problem for systems designers. AI Soc 1:37–46. https://doi.org/10.1007/BF01905888
Coyle K (2013) Library linked data: an evolution. Ital J Libr Inf Sci 4(1):53. https://doi.org/10.4403/jlis.it-5443
Crotti Junior A, Debruyne C, O’Sullivan D (2018) An editor that uses a block metaphor for representing semantic mappings in linked data. In: European semantic web conference (ESWC). Springer, Cham, pp 28–33. https://doi.org/10.1007/978-3-319-98192-5_6
Cruz IF, Antonelli FP, Stroe C (2009) AgreementMaker: efficient matching for large real-world schemas and ontologies. In: Proceedings of the VLDB endowment, vol 2, no 2, pp 1586–1589. https://doi.org/10.14778/1687553.1687598
Cruz IF, Stroe C, Caimi F, Fabiani A, Pesquita C, Couto FM, Palmonari M (2011) Using AgreementMaker to align ontologies for OAEI 2011. In: ISWC international workshop on ontology matching (OM), vol 814, pp 114–121
Das S, Sundara S, Cyganiak R (2012) R2RML: RDB to RDF mapping langauge. https://www.w3.org/TR/r2rml/
De Melo G (2013) Not quite the same: identity constraints for the web of linked data. In: Proceedings of the 27th AAAI conference on artificial intelligence, vol 27, no 1. https://ojs.aaai.org/index.php/AAAI/article/view/8468
Debattista J, McKenna L, Brennan R (2018) Understanding information professionals: a survey on the quality of linked data sources for digital libraries. In: 2018 conference on ontologies, databases, and applications of semantics (ODBASE). https://doi.org/10.1007/978-3-030-02671-4_32
Deliot C (2014) Publishing the British National Bibliography as linked open data. Catal Index 174:13–18
Deliot C, Wilson N, Costabello L, Vandenbussche PY (2017) The British National Bibliography: who uses our linked data?. In: International conference on Dublin core and metadata applications, pp 24–33
Dezani-Ciancaglini M, Horne R, Sassone V (2012) Tracing where and who provenance in linked data: a calculus. Theoret Comput Sci 464:113–129. https://doi.org/10.1016/j.tcs.2012.06.020
Farrell S (2016) Field Studies. Nielsen Norman Group. https://www.nngroup.com/articles/field-studies/
Ferrara A, Nikolov A, Scharffe F (2011) Data linking for the semantic web. Int J Semant Web Inf Syst (IJSWIS) 7(3):46–76. https://doi.org/10.4018/jswis.2011070103
Fisher R (1919) XV—the correlation between relatives on the supposition of Mendelian inheritance. Trans R Soc Edinb 52(2):399–433. https://doi.org/10.1017/S0080456800012163
Guerrini M, Possemato T (2016) From record management to data management: RDA and new application models BIBFRAME, RIMMF, and OliSuite/WeCat. Catalog Classif Q 54(3):179–199. https://doi.org/10.1080/01639374.2016.1144667
Halpin H, Hayes PJ, McCusker JP, McGuinness DL, Thompson HS (2010) When owl: sameas isn’t the same: an analysis of identity in linked data. In: International semantic web conference. Springer, Berlin, pp 305–320. https://doi.org/10.1007/978-3-642-17746-0_20.
Hannemann J, Kett J (2010) Linked data for libraries. In: Proceedings of the world library and information congress, 76th IFLA general conference and assembly. Gothenburg, pp 1–11
Harris S, Seaborne A, Prud’hommeaux E (2013) SPARQL 1.1 Query Language. W3C Recommendation. http://www.w3.org/TR/sparql11-query/
Haslhofer B, Isaac A (2011) data.europeana.eu: the Europeana linked open data pilot. In: International conference on dublin core and metadata applications, pp 94–104
Hevner AR, March ST, Park J, Ram S (2004) Design science in information systems research. MIS Q. https://doi.org/10.2307/25148625
Hevner A, Chatterjee S (2010) Design science research in information systems. In: Design research in information systems. Springer, Boston, pp 9–22
Hoekstra R, Groth P (2013) Linkitup: link discovery for research data. In: 2013 AAAI fall symposium series, pp 28–35
Jaffri A, Glaser H, Millard IC (2008) URI disambiguation in the context of linked data. In: 1st workshop on linked data on the web (LDOW). http://eprints.soton.ac.uk/id/eprint/265181
Jiménez-Ruiz E, Grau BC (2011) LogMap: logic-based and scalable ontology matching. In: International semantic web conference. Springer, Berlin, pp 273–288. https://doi.org/10.1007/978-3-642-25073-6_18
Jiménez-Ruiz E, Grau BC, Horrocks I (2012) LogMap and LogMapLt results for OAEI 2012. Ontol Matching. https://doi.org/10.5555/2887596.2887609
Krug S (2014) Don't make me think, revisited: a common sense approach to web usability, 3rd edn. New Riders, Peachpit, Pearson Education, San Francisco. https://doi.org/10.5555/2663393
Kruskal WH, Wallis WA (1952) Use of ranks in one-criterion variance analysis. J Am Stat Assoc 47:583–621. https://doi.org/10.2307/2280779
Lee YW, Strong DM, Kahn BK, Wang RY (2002) AIMQ: a methodology for information quality assessment. Inf Manag 40(2):133–146. https://doi.org/10.1016/S0378-7206(02)00043-5
Lewis JR (1995) IBM computer usability satisfaction questionnaires: psychometric evaluation and instructions for use. Int J Hum Comput Interact 7(1):57–78. https://doi.org/10.1080/10447319509526110
Lewis JR (2002) Psychometric evaluation of the PSSUQ using data from five years of usability studies. Int J Hum Comput Interact 14(3–4):463–488. https://doi.org/10.1080/10447318.2002.9669130
Lewis JR (1992) Psychometric evaluation of the post-study system usability questionnaire: the PSSUQ. In: Proceedings of the human factors society annual meeting, vol 36, no 16. SAGE Publications, Los Angeles, pp 1259–1260. https://doi.org/10.1177/154193129203601617.
Lowdermilk T (2013) User-centered design: a developer’s guide to building user-friendly applications. O’Reilly Media Inc, Sebastopol
Malmsten M (2008) Making a library catalogue part of the semantic web. Paper presented at the international conference on dublin core and metadata applications-metadata for semantic and social applications 22–26 September 2008, Berlin (DC-2008)
Malmsten M (2009) Exposing library data as linked data. Paper presented at the IFLA satellite preconference sponsored by the information technology section emerging trends in technology: libraries between Web 2.0, Semantic Web and Search Technology, Florence
Mann HB, Whitney DR (1947) On a test of whether one of two random variables is stochastically larger than the other. Ann Math Stat. https://doi.org/10.1214/aoms/1177730491
Manola F, Miller E (2004) RDF primer. https://www.w3.org/TR/rdf-primer/
McGuinness DL, van Harmelen (2004). OWL web ontology language. https://www.w3.org/TR/owl-features/
McKenna L, Debruyne C, O'Sullivan D (2018) Understanding the position of information professionals with regards to linked data: a survey of libraries, archives and museums. In: 2018 ACM/IEEE on joint conference on digital libraries. https://doi.org/10.1145/3197026.3197041
McKenna L, Debruyne C, O'Sullivan D (2019a) Modelling the provenance of linked data interlinks for the library domain. In: Companion proceedings of the 2019 world wide web conference. https://doi.org/10.1145/3308560.3316518
McKenna L, Debruyne C, O'Sullivan D (2019b) NAISC: an authoritative linked data interlinking approach for the library domain. In: 2019 ACM/IEEE joint conference on digital libraries. https://doi.org/10.1109/JCDL.2019.00012
Moreau L, Hartig O, Simmhan Y, Myers J, Lebo T, Belhajjame K, Miles S, Soiland-Reyes S (2013) PROV-AQ: provenance access and query. http://w3.org/TR/prov-aq/
Nentwig M, Hartung M, NgongaNgomo AC, Rahm E (2017) A survey of current link discovery frameworks. Semantic Web 8(3):419–436. https://doi.org/10.3233/SW-150210
Neubauer G (2017) Visualization of typed links in Linked Data. Mitteilungen Der Vereinigung Österreichischer Bibliothekarinnen & Bibliothekare 70(2):179–199
Ngomo ACN, Auer S (2011) Limes—a time-efficient approach for large-scale link discovery on the web of data. In: Proceedings of IJCAI. /https://doi.org/10.5555/2283696.2283783
Nielsen J, Landauer T (1993) A mathematical model of the finding of usability problems. Hum Factors Comput Syst (CHI). https://doi.org/10.1145/169059.169166
Papaleo L, Pernelle N, Saïs F, Dumont C (2014) Logical detection of invalid sameas statements in RDF data. In: International conference on knowledge engineering and knowledge management. Springer, Cham, pp 373–384. https://doi.org/10.1007/978-3-319-13704-9_29
Paris PH, Hamdi F, Cherfi SSS (2019) Interlinking RDF-based datasets: a structure-based approach. Proc Comput Sci 159:162–171. https://doi.org/10.1016/j.procs.2019.09.171
Paris PH (2018) Assessing the Quality of owl: sameAs links. In: European semantic web conference. Springer, Cham, pp 304–313. https://doi.org/10.1007/978-3-319-98192-5_49
Pearson K (1895) Notes on the history of correlation. Proc R Soc Lond 58:240–242. https://doi.org/10.2307/2331722
Pesch O, Miller E (2016) Using BIBFRAME and library linked data to solve real problems: an interview with Eric Miller of Zepheira. Ser Libr 71(1):1–8. https://doi.org/10.1080/0361526X.2016.1183159
PREMIS Editorial Committee (2015) PREMIS data dictionary for preservation metadata. https://www.loc.gov/standards/premis/v3/premis-3-0-final.pdf
Raad J, Beek W, Van Harmelen F, Pernelle N, Saïs F (2018) Detecting erroneous identity links on the web using network metrics. In: International semantic web conference. Springer, Cham, pp 391–407. https://doi.org/10.1007/978-3-030-00671-6_23
Riva P, Le Boeuf P, Žumer M (2016) FRBR—library reference model. http://www.ifla.org/files/assets/cataloguing/frbr-lrm/frbr-lrm_20160225.pdf
Rosala, M. (2019). How to analyze qualitative data from UX Research: thematic analysis. https://www.nngroup.com/articles/thematic-analysis/
Schilling V (2012) Transforming library metadata into linked library data. Association for Library Collections & Technical Services (ALCTS). American Library Association. http://www.ala.org/alcts/resources/org/cat/research/linked-data
Seeman D, Goddard L (2015) Preparing the way: creating future compatible cataloging data in a transitional environment. Catalog Classif Q 53(3–4):331–340. https://doi.org/10.1080/01639374.2014.946573
Simon A, Wenz R, Michel V, Di Mascio A (2013) Publishing bibliographic records on the web of data: opportunities for the BnF (French National Library). In: Extended semantic web conference (ESWC). Springer, Berlin, pp 563–577. https://doi.org/10.1007/978-3-642-38288-8_38
Spearman C (1904) The proof and measurement of association between two things. Am J Psychol 15:72–101. https://doi.org/10.2307/1422689
Student (Gosset, W.S) (1908) The probable error of a mean. Biometrika 6(1):1–25. https://doi.org/10.2307/2331554
Summers E, Isaac A, Redding C, Krech D (2008) LCSH, SKOS and linked data. In: The international conference on Dublin core and metadata applications-metadata for semantic and social applications, 22–26 September, Berlin. https://doi.org/10.5555/1503418.1503422
Tukey J (1949) Comparing individual means in the analysis of variance. Biometrics 5(2):99–114. https://doi.org/10.2307/3001913
Usability First (2015) Introduction to User-Centered Design. http://usabilityfirst.com/about-usability/introduction-to-user-centered-design/
Van Den Haak M, De Jong M, Schellens P (2003) Retrospective vs. concurrent think-aloud protocols: testing the usability of an online library catalogue. Behav Inf Technol 22(5):339–351. https://doi.org/10.1080/0044929031000
Vila-Suero D, Gómez-Pérez A (2013) datos.bne.es and MARiMbA: an insight into library linked data. Library Hi Tech 31(4):575–601. https://doi.org/10.1108/LHT-03-2013-0031
Vila-Suero D, Villazón-Terrazas B, Gómez-Pérez A (2013) datos.bne.es: a library linked dataset. Semantic Web 4(3):307–313. https://doi.org/10.5555/2786071.2786083
Virzi RA (1992) Refining the test phase of usability evaluation: how many subjects is enough? Hum Factors 34(4):457–468
W3C (2015) Linked data. from http://w3.org/standards/semanticweb/data
Wiederhold RA, Reeve GF (2021) Authority control today: principles, practices, and trends. Catalog Classif Q 59(2–3):129–158. https://doi.org/10.1080/01639374.2021.1881009
Wieringa RJ (2014) Design science methodology for information systems and software engineering. Springer, Berlin. https://doi.org/10.1177/001872089203400407
Zaveri A, Rula A, Maurino A, Pietrobon R, Lehmann J, Auer S (2016) Quality assessment for linked data: a survey. Semantic Web 7(1):63–93. https://doi.org/10.3233/SW-150175
Funding
Open Access funding provided by the IReL Consortium. This research was conducted with the financial support of Science Foundation Ireland under Grant Agreement No. #13/RC/2106 at the ADAPT SFI Research Centre at Trinity College Dublin. The ADAPT SFI Centre for Digital Content Technology is funded by Science Foundation Ireland through the SFI Research Centres Programme and is co-funded under the European Regional Development Fund (ERDF) through Grant #13/RC/2106_P2.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Ethical approval and consent
Full ethical approval was received from the School of Computer Science and Statistics, Trinity College Dublin, for all experiments conducted as part of this research. Research participants provided informed consent prior to partaking in the research.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
McKenna, L., Debruyne, C. & O’Sullivan, D. Using Linked Data to create provenance-rich metadata interlinks: the design and evaluation of the NAISC-L interlinking framework for libraries, archives and museums. AI & Soc 37, 921–947 (2022). https://doi.org/10.1007/s00146-021-01373-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00146-021-01373-z